Неправильний код має виглядати неправильним
Автор: Joel Spolsky
Стаття: Making Wrong Code Look Wrong
Дата публікації: 11 травня 2005 року
Переклав: Олексій Мироненко
Редакторка: Олена Поліщук
Повертаючись назад у Вересень 1983 року, пригадую той момент як я щойно влаштувався на свою першу реальну роботу - Oranim, великий хлібопекарський завод в Ізраїлі, який виробляв близько 100 000 хлібин кожної ночі у шістьох величезних пічках розміром з авіаносець.
Я не міг собі навіть уявити, який безлад я побачу вперше зайшовши у пекарню. Печі були в жовтих плямах, машини були іржавими, повсюди було мастило.
Я спитав: “Тут завжди так брудно?”.
“Що? Про що ти говориш?” - перепитав мене менеджер. “Ми тільки закінчили прибирання. Тут не було так чисто вже декілька тижнів.” - додав він.
Ох… хлопче…
Я починав свій ранок з прибирання приміщення і тільки через пару місяців я усвідомив, що він мав на увазі. В пекарні чисто - це коли нема залишків тіста в машинах. Чисто - коли нема тіста, що бродить, в смітнику. Чисто - означає відсутність тіста на підлозі.
Чистота не означала, що поверхні печей мають бути гарними, білими, та свіжопофарбованими. Фарбування печей проводиться раз в десятиліття, а не кожного дня. Чисто - це не про відсутність мастила. Насправді, там було багато різних машин, а тонкий шар чистого мастила зазвичай означав що машину тільки що привели до ладу.

Ви повинні були навчитися розуміти концепцію чистоти в пекарні. Для сторонньої людини було неможливо відразу зрозуміти, чисто в цьому місці, чи ні. Відвідувач не міг сказати, чи чисто всередині тістоокруглювача, лише за його зовнішнім виглядом. Гість би звернув увагу лише на той факт, що стара піч має вицвіле зовнішнє покриття, оскільки те покриття було дійсно великим і одразу кидалося в очі. Але для пекаря байдуже, чи пожовтіла трохи поверхня печі, чи ні. Адже хліб з неї все одно смакував так само добре.
Вже після пари місяців роботи в пекарні ви будете спроможні бачити чистоту.
З кодом все те саме.
Коли ви новачок в програмуванні і намагаєтесь читати код новою мовою він увесь виглядає незбагненним. Допоки ви не зрозумієте цю мову програмування, ви будете бачити лише явні синтаксичні помилки.
На першому етапі навчання ви вчитеся розпізнавати речі, які ми зазвичай називаємо стилем коду (англ. code style). То ж ви почнете помічати частини коду з невірним відступом та змінні з Незвично Великими літерами у назві.
І на цьому етапі ви, скоріше за все, кажете: “Лев Левченко, ми повинні тут узгодити стиль коду!” та витратите увесь наступний день для написання правил стилю коду для вашої команди, а наступного тижня тільки і будете сперечатись про Єдино Правильний Стиль Розміщення Дужок, а вже три тижні потому - переписувати старий код, щоб він відповідав вимогам Єдино Правильного Стилю Розміщення Дужок, доки ваш менеджер не спіймає вас та не накричить на вас за безглузду витрату часу на те, що не принесе грошей. Отож ви вирішите, що не так вже й погано працювати над форматуванням коду лише за необхідності його змінити, і тому будете мати лишень половину коду в Єдино Правильному Стилі Розміщення Дужок та зовсім скоро забудете про все це, перескочивши на якусь іншу неважливу для заробляння грошей ідею на кшталт заміни одного класу рядків на інший клас рядків.
З часом, коли ви вдосконалите свої навички програмування в конкретному середовищі, ви почнете бачити й інші речі. Речі, які повністю відповідають вашим стандартам кодування, але які чомусь будуть турбувати вас.
Наприклад, у C:
char* dest, src;
Цей код відповідає вашим стандартам та стилю кодування, і, можливо, так дійсно було задумано, але ви вже маєте достатньо досвіду написання коду на C та відмітите, що змінна dest задекларована як вказівник на char, а змінна src лише як char. Навіть, якщо саме це і малось на увазі, є вірогідність того, що це не так. Цей код трохи не приємно пахне.
Трохи складніший випадок:
if (i != 0)
foo(i);
В цьому разі код на 100% правильний. Він відповідає більшості стандартам та стилям написання коду та з ним нічого не може статись поганого, але той факт, що тіло оператора if-конструкції, яке не відокремлене фігурними дужками, може вас бентежити, ви можете передчувати, що хтось може вставити туди інший рядок коду:
if (i != 0)
bar(i);
foo(i);
тобто якщо забути додати фігурні дужки, то випадково можна зробити foo(i) безумовним! Отже, коли ви бачите частини коду без фігурних дужок, ви можете відчувати майже невловиму тривогу.
Отже наразі я навів 3 ступені навичок програміста:
- Ви не відрізняєте гарний та поганий код.
- Ви маєте поверхневе уявлення про гарний код, здебільшого через відповідність до стандартів та стилю коду.
- Ви починаєте вловлювати натяки на поганий код настільки, що це починає вас дратувати, та змушує вас виправити такий код.
Ще є найвищий рівень, про який я саме і хотів би поговорити:
- Ви свідомо проектуєте свій код таким чином, щоб ваше чуття поганого коду робило ваш код дійсно схожим на гарний.
Це майже мистецтво: робити зрозумілий код, використовуючи домовленості, які, в разі наявності в коді помилок, будуть кричати вам з екрану про це.
Тепер я наведу вам невеликий приклад та покажу вам загальне правило, використовуючи яке, ви зможете винаходити ці домовленості зрозумілості коду та, врешті-решт, це призведе до виправдання справжньої Угорської Нотації, а не тої, від якої людей нудить, та до критики винятків у певних випадках.
Але якщо ви настільки переконані що Угорська Нотація це Погана Штука, та що винятки - найкращий винахід з часів винаходу шоколадно-молочного коктейлю, що ви й навіть чути не хочете жодних інших думок з цього приводу, то краще відвідайте Rory та почитайте їхні пречудові комікси замість цього, бо ви не зайдете тут нічого важливого для себе. По факту, вже через хвилинку я збираюся надати приклади коду, які присплять вас швидке аніж встигнуть розізлити. Так от, я думаю план буде таким: спочатку я присплю вас, а потім підсуну ідею, що Угорська Нотація = добре, Винятки = погано поки ви будете сонними і не будете мати бажання сперечатися.
Приклад

Добре. Перейдемо до прикладу. Припустимо ви розробляєте якусь web-програму, оскільки вони, здається, зараз популярні серед молоді.
Є така вразливість безпеки, як Вразливість Міжсайтових Скриптів (англ. Cross Site Scripting Vulnerability) також знана як XSS. Я не буду зараз вдаватись в подробиці: все, що вам необхідно знати - це те, що коли ви розробляєте web-програму, ви повинні бути акуратними у використанні рядків даних, які користувачі вводять у web-формах.
Тож, наприклад, якщо у вас є web-сторінка з питанням “Яке ваше ім’я?” з відповідним полем для вводу і дані з цієї сторінки відправляються на іншу сторінку, яка каже “Привіт, Сашко!” (припустимо користувача звуть Сашко), то тут є вразливість, оскільки користувач може ввести будь який HTML або JavaScript замість імені “Сашко” і цей код може робити погані речі, які, як буде здаватися, будуть походити від вас, як-от, наприклад, прочитати cookie-файли та переслати їх на сайт зловмисного Доктора Евіла.
Давайте розглянемо це у псевдокоді. Уявімо що
s = Request("name")
читає вхідні дані від HTML-форми (параметр POST запиту). Якщо ви десь використаєте такий код:
Write "Hello, " & Request("name")
ваш сайт буде вразливий до XSS атак. І це все, що потрібно.
Натомість ви можете закодувати дані перед тим, як повернути їх назад у HTML. Закодувати - тут мається на увазі замінити " на ", а > замінити на >, і т.п. Тоді
Write "Hello, " & Encode(Request("name"))
буде повністю безпечним кодом.
Усі рядки, отримані від користувача, - небезпечні. Небезпечний рядок не можна виводити без кодування.
Давайте спробуємо придумати угоду про кодування, яка гарантуватиме, що якщо ви колись припуститеся цієї помилки, код просто виглядатиме неправильно. Якщо неправильний код, принаймні, виглядає неправильно, тоді у нього є шанс бути виявленим тим, хто працює над цим кодом, або переглядає його.
Можливе рішення #1
Одним з рішень є кодування всіх рядків одразу, щойно вони надійшли від користувача:
s = Encode(Request("name"))
Тож наша домовленість може бути такою: якщо ви десь бачите звертання до Request, яке не заключене у Encode, то такий код потенційно неправильний.
І ви почнете тренувати своє чуття бачити голі Request-ти, оскільки вони порушують правила.
Це буде працювати, в тому сенсі, що поки ви будете слідувати цій домовленості, ви ніколи не спіймаєте XSS помилку, але це, звісно, не найкраща архітектура. Наприклад, ви можете потребувати зберігати рядки даних від користувача десь у базі даних, і тоді не має сенсу їх зберігати закодованими у БД, оскільки ці рядки можуть бути використаними чимось відмінним від HTML сторінки, наприклад програмою з обробки кредитних карток, яка не зрозуміє HTML-закодовані дані. Більшість web-програм розроблені таким чином, що усі рядки не кодуються при внутрішньому використанні, а закодовуються лише в останній момент перед показом на HTML сторінці, і це, ймовірно, правильний підхід.
Нам дійсно необхідно мати можливість довготривалий час зберігати дані у небезпечному форматі.
Що ж, я спробую ще раз.
Можливе рішення #2
А що, якщо ми створимо домовленість, яка буде вказувати на необхідність закодувати рядки перед їх показом?
s = Request("name")
// десь потім:
Write Encode(s)
Тепер, де-б ви не побачили голий Write без використання Encode, ви будете знати, що код невірний.
Що ж, це не легка робота… іноді ви маєте маленькі частини HTML, які ви не в змозі закодувати:
If mode = "linebreak" Then prefix = "<br>" // десь потім: Write prefix
Згідно нашої домовленості це виглядає неправильним, і спонукає нас закодовувати рядки перед показом:
Write Encode(prefix)
Але тепер "<br>", який відповідає за початок нового рядка, буде також закодований у <br> та постане перед користувачем як набір символів < b r >. Що теж не є правильним.
Тож, іноді ви не можете закодувати рядки коли отримуєте їх, а іноді не можете закодувати їх перед видачею, тоді жодна з цих пропозицій не буде працювати. А без домовленості ми й досі ризикуємо що ви зробите щось подібне до такого:
s = Request("name")
...десь набагато пізніше...
name = s
...ще пізніше...
recordset("name") = name // збережемо ім'я у БД в колонці "name"
...днями пізніше...
theName = recordset("name")
...і можливо навіть місяцями пізніше...
Write theName
Ми не забули закодувати рядки? Немає жодного місця де б ви могли відчути помилку. Немає де “принюхуватись”. Якщо ви маєте багато коду на схожого на цей, ви матимете тонни детективної роботи аби простежити кожний рядок перед показом та впевнитись що його було закодовано.
Правильне рішення
Отже, давайте я запропоную домовленість, яка працює. Ми повинні мати лише одне правило:
Усі рядки даних від користувача мають зберігатись у змінних (або в базі даних) з іменем, яке починається з префіксу
us(від англ. Unsafe String - небезпечний рядок).
Усі рядки які вже закодовано, або джерело яких є безпечним, повинні зберігатись у змінних з іменем, яке починається з префіксуs(від англ. Safe string - безпечний рядок).
Тож дайте мені тепер переписати той-же код, змінюючи тільки імена змінних відповідно до нашої нової домовленості.
us = Request("name")
...десь пізніше...
usName = us
...і ще пізніше...
recordset("usName") = usName
...днями пізніше...
sName = Encode(recordset("usName"))
...і можливо навіть місяцями пізніше...
Write sName
Я хочу зауважити одну деталь в новій домовленості, якщо ви зробите помилку з безпечністю рядка, ви завжди зможете це побачити в розрізі одного рядка коду, якщо будете дотримуватися домовленості кодування:
s = Request("name")
апріорі неправильно, оскільки результат з Request записано у змінну, ім’я котрої починається з s, що проти правил. Результат з Request завжди небезпечний і має завжди зберігатись у змінних, ім’я яких починається з us.
-
us = Request("name")
завжди вірно. -
usName = us
завжди вірно. -
sName = us
однозначно невірно. -
sName = Encode(us)
точно вірно. -
Write usName
точно невірно. -
Write sName
вірно, так само як і -
Write Encode(usName)
теж вірно.
Кожний рядок коду може бути проінспектований окремо, і якщо кожен окремий рядок правильний, то і увесь блок коду теж правильний.
Зрештою, за допомогою використаної домовленості, ваші очі зможуть навчитися бачити Write usXXX і ви будете знати що це неправильно, а також ви завжди будете знати, як це виправити. Я розумію, на початку, це буде трошки складно одразу бачити невірний код, але після двох-трьох тижнів ваші очі адаптуються, так само, як і робітники пекарні, які навчились бачити це серед величезних машин пекарні та миттєво казати: “боже, ніхто не вичистив зсередини формовщик, що за ліниві корови цим займались?”.
По факту, ми можемо трохи розширити правило та перейменувати (або огорнути) Request та Encode у UsRequest та SEncode, іншими словами, функції, які повертають рядки небезпечні та рядки безпечні будуть починатись відповідно з Us та S, так само як і змінні. Тож тепер код буде виглядати так:
us = UsRequest("name")
usName = us
recordset("usName") = usName
sName = SEncode(recordset("usName"))
Write sName
Бачили, що я зробив? Тепер ви можете перевіряти, чи починаються обидві сторони знаку дорівнює з однакових префіксів, та бачити помилки.
us = UsRequest("name") // правильно, обидві сторони починаються з US
s = UsRequest("name") // помилка
usName = us // правильно
sName = us // однозначно помилка
sName = SEncode(us) // точно правильно
До біса, я можу піти навіть далі у найменуванні, та назвати Write як WriteS, а SEncode як SFromUs:
us = UsRequest("name")
usName = us
recordset("usName") = usName
sName = SFromUs(recordset("usName"))
WriteS sName
Це може зробити помилки навіть більш явними. Ваші очі навчаться “бачити” поганий код і це допоможе вам знаходити незрозумілі помилки безпеки в процесі звичайного написання та читання коду.
Зробити так, щоб неправильний код виглядав неправильно, це добре, але це не обов’язково найкраще рішення для кожної проблеми безпеки. Це не вбереже від усіх можливих помилок, оскільки ви, мабуть, не дивитесь на кожний окремий рядок коду. Але це, безсумнівно, набагато краще ніж нічого, та я б залюбки хотів би мати домовленість щоб невірний код хоча б виглядав невірним. Ви миттєво відчуєте результат від того, що кожного разу, як очі програміста проходяться рядками коду, вони будуть перевіряти його та запобігати цьому типу помилок.
Примітка від перекладача-програміста.
Правильніше буде автоматизувати процес виявлення подібних помилок, або й взагалі виключити можливість їх виникнення. Наприклад, у мові програмування C++, можна створити відповідні типи safe_string та unsafe_string з можливістю перетворення одного типу в інший. Функція Request має повертати тип unsafe_string а функція Write приймати тип safe_string. Таким чином компілятор буде гарантувати відсутність помилок використання небезпечних даних, та, відповідно, ніякої Угорської Нотації у цьому разі не знадобиться. Вона потрібна там, де засоби мови програмування не дозволяють використовувати достатньо чітку типізацію, наприклад у Visual Basic або C.
Загальне правило
Ця справа, щоб робити неправильний код виглядав неправильно, спирається на те, щоб розміщувати правильні частини ближче одна до одної на екрані. Коли я дивлюсь на рядок коду в намаганні зробити його правильним, мені необхідно знати: безпечний він, чи ні, всюди де цей рядок використовується. Я не хочу, щоб ця інформація була в іншому файлі або на іншій сторінці, до якої потрібно ще гортати. Я хочу мати можливість бачити її прямо тут, а це означає домовленість з іменування змінних.
Існує багато прикладів, де ви можете покращити код, пересунувши його частини ближче одну до одної. Більшість домовленостей кодування мають правила, до прикладу, таких:
- Робіть функції короткими.
- Декларуйте змінні якнайближче до місць їх використання.
- Не використовуйте макроси для створення власної мови програмування.
- Не використовуйте конструкцію
goto. - Не розміщуйте закриваючі дужки на відстані більшої, ніж одна сторінка, від відповідних відкриваючих дужок.
Спільним для всіх цих правил є те, що вони намагаються розмістити якнайближче фізично релевантну інформацію, що саме робить код насправді. Це підвищує шанси, що ваші очі охоплять все, що там відбувається.
Загалом, я хочу зазначити, що трохи побоююсь функціоналу приховування у мовах програмування. Коли ви бачите код
i = j * 5;… в C ви знаєте, як мінімум що
j помножується на 5 та результат записується у i.
Але коли ви побачите той самий код на C++, ви нічого не зрозумієте. Нічогісінько. Єдиний спосіб дізнатись що насправді відбувається в C++ - це дізнатись типи i та j які можуть бути задекларовані десь зовсім у іншому місці. Це тому, що j може бути типу, який має перевантажений operator* і він може робити щось страшенно підступне, коли ви намагаєтесь помножити його. А i може бути типу з перевантаженим operator=, і вони можуть бути несумісними, та й автоматичне приведення типів може не спрацювати. Єдиним способом це дізнатись - це не тільки подивитись яких саме типів змінні, а ще й дізнатись точну реалізацію цих типів, і нехай допоможе вам Бог, якщо десь там буде наслідування, оскільки тепер ви маєте тинятися ієрархією класів на самоті, намагаючись знайти де той код насправді є. Якщо там десь є ще й поліморфізм - то це дійсно проблема, оскільки тепер не достатньо просто знати задекларовані типи i та j, тепер ви маєте знати, які типи вони мають саме зараз, що може спонукати до перегляду усього супутнього коду і ви можете так ніколи і не бути впевненим, що усе передивились та в усьому розібрались (фух!).
Коли ви бачите i=j * 5 в C++ ви залишаєтесь наодинці, і це те, що на мою думку, зменшує здатність віднайти вірогідні проблеми лише переглядаючи код.
Нічого з цього не мало б мати значення. Коли ви зверхньо робите речі подібні на перевантаження operator* це має допомагати вам створити гарну куленепробивну абстракцію. Боже,
j це Рядок у Форматі Unicode, а множення його на ціле число це точно очевидна та гарна абстракція до приведення Традиційної Китайської до Стандартної Китайської, чи не так?
Проблеми в тому, авжеж, що не існує куленепробивних абстракцій. Я достатньо про це говорив у статті The Law of Leaky Abstractions тож не буду повторювати себе.
Scott Meyers зробив собі кар’єру показуючи усім як вони підводять та кусають вас, як мінімум у C++. (Між іншим, нещодавно вийшло повністю переписане третє видання його книжки Ефективний C++ (англ. Effective C++), замовте собі копію прямо зараз!)
Добре.
Але я відволікся від нашої теми. Краще підсумую все, що було вже сказано:
Шукайте домовленості, через які неправильний код буде виглядати неправильно. Отримання інформації, розташованої в одному місці на екрані у вашому коді, дає змогу побачити певні типи проблем і негайно їх виправити.
Примітка від перекладача-програміста.
Вищеописану проблему краще вирішувати за допомогою зрозумілих та інформаційно-наповнених імен змінних та їх типів, та обов’язково позбавлятися магічних чисел. Замість i може бути цілком зрозуміле ім’я item_volumetric_weight (або item_weight_by_volume), замість j може бути item_weight а замість магічного числа 5 може бути kWeightToVolumeMultiplier:
const int kWeightToVolumeMultiplier = 5; ... item_volumetric_weight = item_weight * kWeightToVolumeMultiplier;
Це звісно довше, але надає набагато більше інформації тут і зараз, додає вашому коду контекст.
Я угорець

Давайте тепер повернемось до багатостраждальної Угорської Нотації.
Угорська Нотація була придумана програмістом Charles Simonyi який працював тоді в Microsoft. Одним з важливих проєктів, над яким працював Simonyi в Microsoft, був Word. Фактично, він очолював створення першого у світі WYSIWYG редактора, по типу так званого Bravo у Xerox Parc.
У WYSIWYG редакторі є вікна з прокруткою, тож усі координати мають інтерпретуватись або відносно вікна, або відносно сторінки, що є великою різницею, і тому дуже важливо їх відрізняти.
Я припускаю, що це стало однією з багатьох причин, чому Simonyi почав використовувати щось, що згодом назвали Угорською Нотацією. Це виглядало як угорська, а сам Simonyi був з Угорщини, тому і назва така. У версії Угорської Нотації від Simonyi кожна змінна мала префікс-тег маленькими літерами, котрий відображав зміст того, що зберігала в собі змінна.
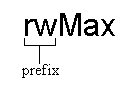
Я використовую слово зміст не безпідставно, оскільки Simonyi помилково використав слово тип у своїх документах, а покоління програмістів непевні тепер, що він мав на увазі.
Якщо ви прискіпливіше прочитаєте документи Simonyi, те, до чого він дійшов, є та сама ідея про домовленість іменування, яку я використав у прикладі вище, де ми вирішили, що us відповідає “unsafe string”, а s відповідає “safe string”. І те і інше є рядками. Компілятор не допоможе вам, якщо ви призначите один рядок до іншого, а Intellisense не підкаже вам. Але вони семантично різні, мають бути інтерпретовані по різному та використані в різний спосіб, має бути викликана якась функція-конвертор для передачі значення з одного в інший, інакше ви матимете помилку під час роботи програми. Це якщо вам повезе.
Оригінальний концепт Угорської Нотації від Simonyi всередині Microsoft був названий як Програмна Угорська (англ. Apps Hungarian), оскільки її використовували у Підрозділі Програм, тобто Word та Excel. У вихідному коді Excel ви можете побачити багато rw та col, і коли ви їх бачите, то розумієте, що вони позначають відповідно рядки та колонки. Звісно, вони усі є цілими числами, але немає сенсу призначати їх значення одні одним. У Word, як мені розказували, ви можете побачити багато xl та xw, де xl позначає “горизонтальні координати відносно макету” (l від англ. layout), а xw позначає “горизонтальні координати відносно вікна” (w від англ. window). І те і інше є числами. Не взаємозамінними. В обох програмах ви побачите багато cb для позначення “кількості байт” (від англ. “count of bytes”). Так, і це теж числа, але це дає так багато при звичайному погляді на ім’я змінної. Кількість байт може позначати розмір буферу. Та коли ви побачите xl = cb, що ж, час свистіти у “Свисток Поганого Коду”, адже це безперечно помилковий код, хай навіть і xl і cb є числами, це повне безумство призначати кількість байт до горизонтального зміщення у пікселях.
У Програмній Угорській префікси використовуються для функцій так само як і для змінних. Я ніколи не бачив вихідний код Word, але ставлю долари проти пончиків, що там є функція під назвою YlFromYw, яка конвертує горизонтальні координати відносно вікна у горизонтальні координати відносно макету. Програмній Угорській відповідає іменування TypeFromType, замість більш традиційного TypeToType щоб кожна функція починалась з назви типу який є її результатом, так само, як я зробив це раніше в прикладі, коли перейменував Encode у SFromUs. По факту, у Програмній Угорській, функція Encode має мати ім’я SFromUs. Програмна Угорська не дає вам шансу назвати цю функцію інакше. І це добре, адже тоді вам треба запам’ятовувати на одну річ менше, та ви не будете гадати, яке саме кодування мається на увазі під словом Encode: у вас вже є більш чітка назва.
Програмна Угорська була напрочуд важлива в період програмування на C, де компілятор не має потужної системи користувацьких типів
Але потім щось пішло не так.
Темна сторона взяла верх над Угорською Нотацією.
Скоріше за все ніхто не знає чому та як, але сталось так, що команда Windows, яка відповідала за документацію, ненавмисно винайшла щось, що потім стало загальновідомим під назвою Системна Угорська (англ. Systems Hungarian).
Хтось колись прочитав документи Simonyi, де він використав слово “тип”, та зрозумів під цим саме тип, той тип, який перевіряє компілятор. Але він не це мав на увазі. Він досить обережно пояснив що саме він має на увазі під словом “тип”, але це не допомогло. Шкоди було вже завдано.
Програмна Угорська мала дуже корисні, наповнені сенсом префікси, як от ix для означення індексу масиву (від англ. index), c для означення кількості (від англ. count), d для означення різниці між двома числами (на приклад, dx означає ширина), та інші подібні.
Системна Угорська на противагу мала значно менш корисніші префікси, наприклад: l для означення цілих чисел (від англ. long) та ul для означення беззнакових цілих чисел (від англ. unsigned long) та dw для означення подвійного процесорного слова (від англ. double word), який, насправді, і є беззнаковим цілим числом. У Системній Угорській префікси говорять вам лише про актуальний тип даних змінної.
Це було ледь вловиме, але повністю неправильне розуміння мети та ідеї Simonyi, і лиш показує, якщо писати заплутаною академічною прозою - ніхто не зрозуміє її, а ваші ідеї хибно сприймуть, та потім хибно інтерпретовані ідеї будуть висміяні, навіть коли вони стануть вже не вашими ідеями. Тож у Системній Угорській ви мали багато dwFoo у значенні “подвійне процесорне слово foo”, і до речі, той факт, що змінна є подвійним процесорним словом взагалі майже нічого корисного вам не каже. Тож не дивно, що люди збунтувались проти Системної Угорської.
Системну Угорську було оприлюднено по всіх усюдах. Це стандарт всієї документації Windows програмування. Вона була широко розповсюджена через книжки, такі як “Programming Windows” від Charles Petzold, яка являється біблією розуміння Windows програмування, тож вона швидко стала панівною формою Угорської Нотації, навіть всередині Microsoft, де лишень декілька програмістів поза командами Word та Excel розуміли, яку ж вони зробили помилку.
І тоді прийшло Велике Повстання. Зрештою, програмісти, які ніколи не розуміли Угорську Нотацію, в першу чергу помітили, що те незбагненне, що вони використовували, було До біса Набридливим та Вельми Марним, то-ж вони повстали проти нього. Наразі все ще є деякі гарні якості у Системній Угорській, які допомагають бачити помилки. Принаймні, якщо ви використовуєте Системну Угорську, ви будете знати, якого типу даних змінна в тому місці, де ви її використовуєте. Але це далеко не те, що дає Програмна Угорська.
Пік Великого Повстання припав на перший реліз .Net. Microsoft нарешті почала казати людям “Угорська Нотація не рекомендована”. Було велике святкування. Я не думаю, що вони навіть потурбувались сказати чому. Вони просто пройшлись по розділу документації із вказівками щодо найменування та написали “Не використовуйте Угорську Нотацію” в кожному пункті. Угорська Нотація була настільки непопулярна на той момент, що ніхто насправді і не поскаржився, та кожен у світі поза Excel та Word відчув полегшення від того, що більше не доведеться мати справу із дивними правилами найменування, які, на їх думку, не були потрібними у час жорсткої перевірки типів та IntelliSense.
Але і дотепер величезна цінність Програмної Угорської в тому, що вона покращує розміщення коду, що робить його легшим для читання, написання, відлагоджування, підтримки, і що найважливіше, - вона змушує неправильний код виглядати неправильним.
Наостанок залишилась одна річ яку я пообіцяв зробити - ще разочок пройтися по виняткам. Останнього разу, коли я це робив мені було непереливки. У необережному зауваженні на своїй сторінці я написав, що не люблю винятки, оскільки вони є, вочевидь, прихованими goto, що, як на мене, є навіть гірше, ніж goto, які ви можете побачити. Звісно, мільйони людей накинулись на мене. Єдиний, хто пристав на мій захист, був Raymond Chen, який, між тим, є найкращим програмістом у світі, тож йому є що сказати, чи не так?
Є ще дещо про винятки, в контексті цієї статті. Ваші очі вчаться бачити неправильні речі, якщо є що бачити, і це запобігає помилкам. Для того щоб зробити код дійсно надійним, коли ви робите код рев’ю, вам необхідно мати домовленість, яка дозволяє його вірно розміщувати. Іншими словами, чим більше інформації про код ви маєте перед своїми очима, тим краще ви будете виявляти помилки. Коли ви маєте такий код
dosomething(); cleanup();… ваші очі кажуть вам, що може бути з ним не так? Ми завжди очищаємо! Але можливість того, що
dosomething() може створити виняткову ситуацію означає що cleanup() може бути не викликаним. Але це легко виправляється, за використанням finally або чогось на подібного, але я не про це, моя думка в тому, що для того, щоб дізнатися, чи точно буде викликано cleanup(), треба продивитися усю послідовність викликів всередині dosomething(), чи є там щось, що може створити виняток. І це нормально, є речі, на зразок перевірених винятків (англ. checked exceptions), аби було легше з цим, але головне те, що винятки виключають корисне розміщення коду. Вам необхідно ще додатково попрацювати для відповіді на питання, чи робить код все правильно, тому ви не зможете побачити помилковий код, оскільки тепер немає на що дивитись.
Тепер, коли я пишу невеличку програму, для збору купи даних та їх показу один раз на день, авжеж, винятки чудові. Мені потрібно лише ігнорувати усе, що може піти не так, і просто обернути усю цю кляту програму у один великий try/catch, який висилатиме мені листа, якщо щось піде не так. Винятки чудово підходять для нашвидкоруч написаного коду, для скриптів, та для коду, який не є ані критичним, ані життєво важливим. Але якщо ви розробляєте операційну систему, або ядерну електростанцію, або програмне забезпечення для контролю швидкісної пилки, яка використовується при операціях на відкритому серці, винятки є надзвичайно небезпечними.
Я знаю, люди припускатимуть, що я поганенький програміст, що не зміг правильно зрозуміти винятки та не побачив усіх можливостей, якими вони можуть покращити моє життя, якби ж я тільки впустив би винятки у своє серце, але, на жаль. Способом написанням дійсно стабільного коду є намагання використовувати прості підходи, які враховують людські слабкості, а не складні підходи з прихованими ефектами та дирявими абстракціями, які удають безпомилковість програміста.
Більше для прочитання
Якщо ж ви ще досі захоплені винятками, прочитайте статтю Cleaner від Raymond Chen, більш елегантну та важчу для розуміння. “Надзвичайно важко побачити різницю між поганим кодом з використанням винятків та не поганим кодом з використанням винятків… винятки важкі для розуміння, а я недостатньо розумний для їх розуміння.”
Нарікання Raymond про Смерть від Макросів (англ. Death by Macros), A rant against flow control macros, в якій йдеться про інший випадок, де неможливість отримати усю інформацію в одному місці унеможливлює подальшу підтримку коду. “Коли ви бачите код з використанням (макросів), вам необхідно зануритись у файли заголовків для усвідомлення, що ж він таки робить.”
Для ґрунтовного розуміння історії Угорської Нотації почніть з документів Hungarian Notation за оригінальним авторством Simonyi. Doug Klunder представив їх команді Excel у більш зрозумілому вигляді. Більше історій про Угорську Нотацію та як вона була зруйнована письменниками документації читайте у статті Larry Osterman, особливо коментар Scott Ludwig, або статтю Rick Schaut.